OpenAI recently open-sourced their “Whisper” neural net for automatic speech recognition. While this is interesting in its own right, the fact that this is an open-source model that can be run in our own infrastructure may open up some deployment options that were not previously available. Let’s take a closer look.
Getting started with Whisper
Installation
Installing Whisper is much easier than I had feared and basically consists of these three steps:
Create a virtual environment with Python 3.9.9. This is the recommended Python version for Whisper, and even though this is over a year old, better safe than sorry.
I wanted to see how well Whisper works in different languages, so I made two short recordings to use for my initial experiments, one in English - “Hello and welcome to Whisper. This is my first demo.”:
…and one in Danish - “Lad os prøve på dansk og se om den kan oversætte det korrekt.”:
Processing the English audio file through Whisper gave this result:
> whisper 1st_english.wav
100%|███████████████████████████████████████| 461M/461M [00:16<00:00, 28.6MiB/s]
Detecting language using up to the first 30 seconds. Use `--language` to specify the language
Detected language: English
[00:00.000 --> 00:04.000] Hello and welcome to Whisper. This is my first demo.
Flawless transcription! Also notice that on this first run Whisper automatically downloaded the required model data. This also meant that the first run took significantly longer than subsequent runs.
Now for the Danish audio:
> whisper 1st_danish.wav
Detecting language using up to the first 30 seconds. Use `--language` to specify the language
Detected language: English
[00:00.000 --> 00:04.000] There's Pro Podensk, I'll see how I'm doing, how was it to go out?
That’s a terrible transcription, but notice how it reported the detected language as English. Let’s try again but this time tell it that the audio is Danish using the --language argument:
- whisper 1st_danish.wav --language Danish
[00:00.000 --> 00:04.000] Deres proberdensk, og se om den kører sit dekvært.
This is still terrible. In fact I don’t think any Dane reading this transcription would be able to guess what was actually said.
At this point I went back and actually listened to the recordings I made. They are very noisy, but not noisy enough that a native listener wouldn’t understand the content. I tried processing the Danish audio with Google Cloud Speech-to-Text, and it transcribed it flawlessly. Perhaps Whisper is just more sensitive to noise than other speech recognition systems?
Noise reduction
For my first attempt at improving the recognition of the Danish audio using noise reduction, I used Audacity to reduce the noise. This is a semi-manual process where you first select a portion of the audio that should be silent, that is only contains noise, so that Audacity can analyse the noise that is present. In a second step you select the audio to perform noise reduction on based on the analysis performed. This generally leads to quite good results, but cannot be done unattended. Here is the resulting audio:
Whisper produced this transcription:
>whisper 1st_danish_nr_audacity.wav --language Danish
[00:00.000 --> 00:04.000] Der er pro-potensk, og se om den kører siddende korrekt.
While this is a little better, it’s still not good enough to be useful.
Since Audacity’s noise reduction method is unsuited for real-time use, I tried using Gstreamer’s noise reduction from
webrtcdsp using this command-line:
>gst-launch-1.0 filesrc location=1st_danish_mono.wav ! wavparse ! audioconvert ! audioresample ! webrtcdsp echo-cancel=false extended-filter=false gain-control=false high-pass-filter=false ! wavenc ! filesink location=1st_danish_nr_gstreamer.wav
Use Windows high-resolution clock, precision: 1 ms
Setting pipeline to PAUSED ...
Pipeline is PREROLLING ...
Pipeline is PREROLLED ...
Setting pipeline to PLAYING ...
Redistribute latency...
New clock: GstSystemClock
Got EOS from element "pipeline0".
Execution ended after 0:00:00.023411500
Setting pipeline to NULL ...
Freeing pipeline ...
This produced the following audio, which is - to my ears - not quite as clean as what Audacity produced, but noticably less noisy than the original:
From this, Whisper produced:
>whisper 1st_danish_nr_gstreamer.wav --language Danish
[00:00.000 --> 00:04.000] Deres proberdensk, og se om den kører sit dekvært.
Sadly this is precisely the same transcription we got from the original noisy audio.
Better audio recording
Let’s see if we can do better by making a cleaner recording to begin with. The following is another recording of me saying the same thing, but this time I made the recording in a more quiet environment, which is immediately obvious when you hear the recording:
This time Whisper produced this transcription:
>whisper 2nd_danish_mono.wav --language Danish
[00:00.000 --> 00:04.000] Lad os prøve det på dansk og se om den kan oversætte det korrekt.
Flawless transcription in Danish! This illustrates that Whisper can produce impressive transcription results even in “small” languages like Danish provided that the recorded audio is relatively free of noise.
Translation
One of Whisper’s interesting features is that it can not only perform transcription but can actually perform translation into English at the same time. To use this feature all we have to do is add the --task translate argument. Let’s try this with the Danish audio:
>whisper 2nd_danish_mono.wav --language Danish --task translate
[00:00.000 --> 00:04.000] Let's try it in Danish and see if it can translate correctly.
This is a correct English translation, and we got it from the Danish audio in a single step. Quite impressive! And this is not limited to Danish audio. Whisper can do this for all it’s supported languages. Their blog post calls this “Any-to-English speech translation”. Do note, however, that Whisper only supports translation into English - at least at the time of writing.
Real-time usage
So far, we have only seen Whisper used in what you might call “batch mode”, where an audio file is prepared and then processed by Whisper in a separate step and as a whole. Whisper does not directly support real-time processing, where you feed a live audio signal to the model and get back live transcription results. However, several efforts are underway to repurpose Whisper for real-time processing, and I plan to visit this in the future. Real-time transcription would make it possible to use Whisper in many more settings, for instance with digital humans.
Advantages
Whisper’s machine learning models are quite large, and it does require a GPU with CUDA support in order to run, so what might be the advantage of running Whisper in your own infrastructure vs. using one of the available cloud speech recognition services from e.g. Google or Azure? By hosting your own speech recognition engine you can potentially deploy it closer to the other components of your system and thereby reduce latency. This could be important in real-time applications such as digital humans, where users’ overall perceived latency is a critical factor in useability. Hosting your own engine could prove advantageous in terms of privacy - think GDPR. If you can avoid sending audio to a third party, you could reduce your compliance risk.
Last time I used GStreamer to produce a video stream that can be consumed in an Unreal project. I found that in order for this to work it was necessary to produce an RTSP stream, which is a little more complicated than I may have wished. In the meantime I stumbled upon the nifty UE4 GStreamer plugin that allows you to execute a GStreamer pipeline within Unreal Engine itself and render the output directly to a Static Mesh, i.e. to any desired surface.
Using this plugin gives a lot more flexibility in how to stream video into Unreal by eliminating the limitation of using Unreal’s built-in streaming formats. I’ll make good use of this in the next post, but for now here’s a brief example of using the plugin with a static pipeline.
All credit for this plugin goes to its author, who also has a bunch of other interesting projects on Github. Go check them out!
Prerequisites
To use the plug-in all you need are a working GStreamer installation (I’m using version 1.20.1) and Unreal Engine 4.26. After cloning the repository you need to make a couple minor adjustments to the source code so that the plugin can find GStreamer (this is clearly explained in the repository linked above), and then you’re ready to play.
Using the plugin
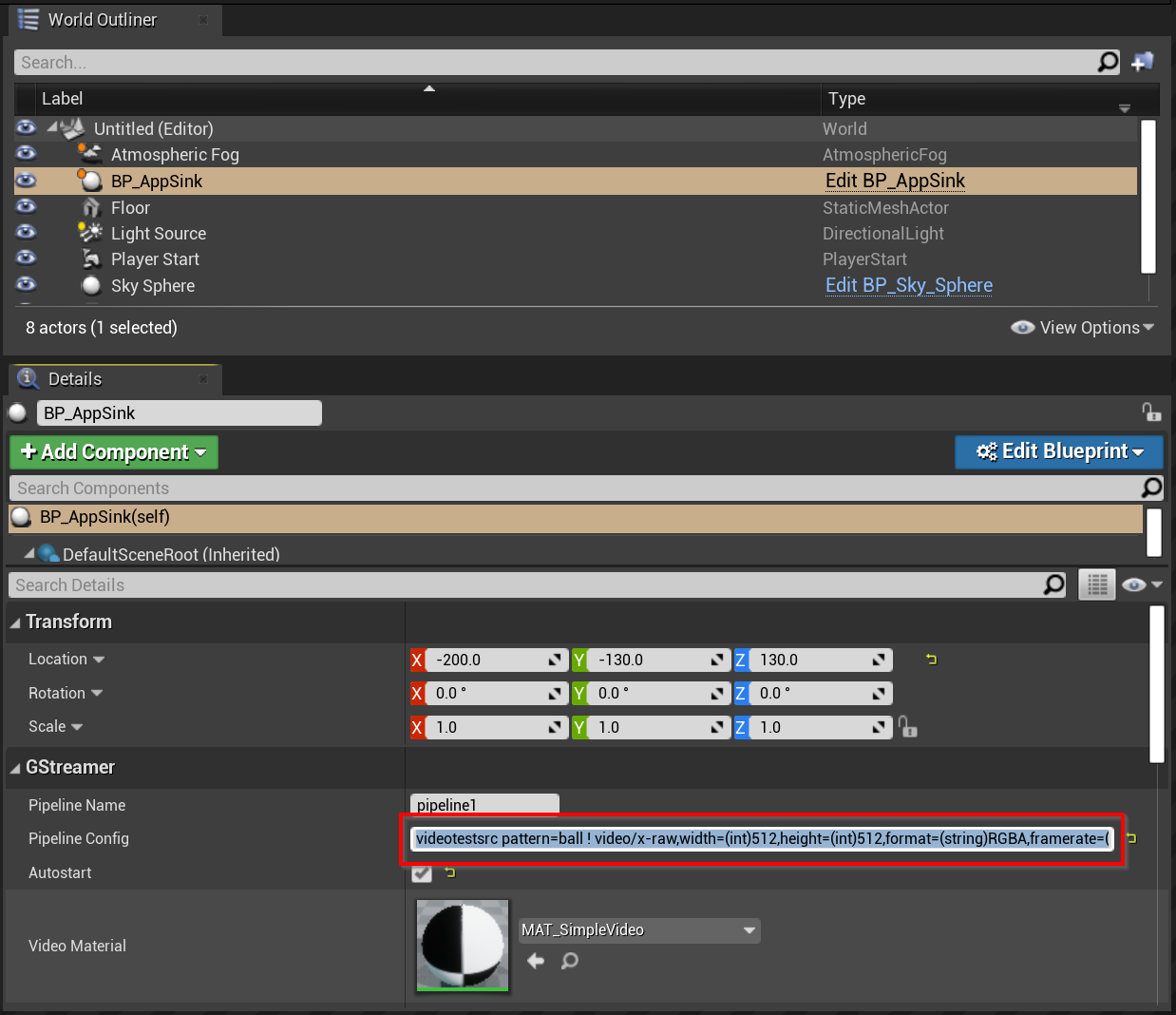
The repository includes sample AppSink and AppSrc Actor blueprints. When configured with a GStreamer video pipeline, the AppSink renders the output of that pipeline to the surfaces of the Actor. By default it renders to both sides of a plane. The AppSrc uses Unreal’s built-in Scene Capture component to capture a rendering from within the Unreal game and use it as input to a GStreamer pipeline. Combining the two, as is done in the example project, allows you to render the captured Unreal scene somewhere else within that very scene - very cool! Below I’ll only illustrate how to use the AppSink just to show how easy it is to get started with.
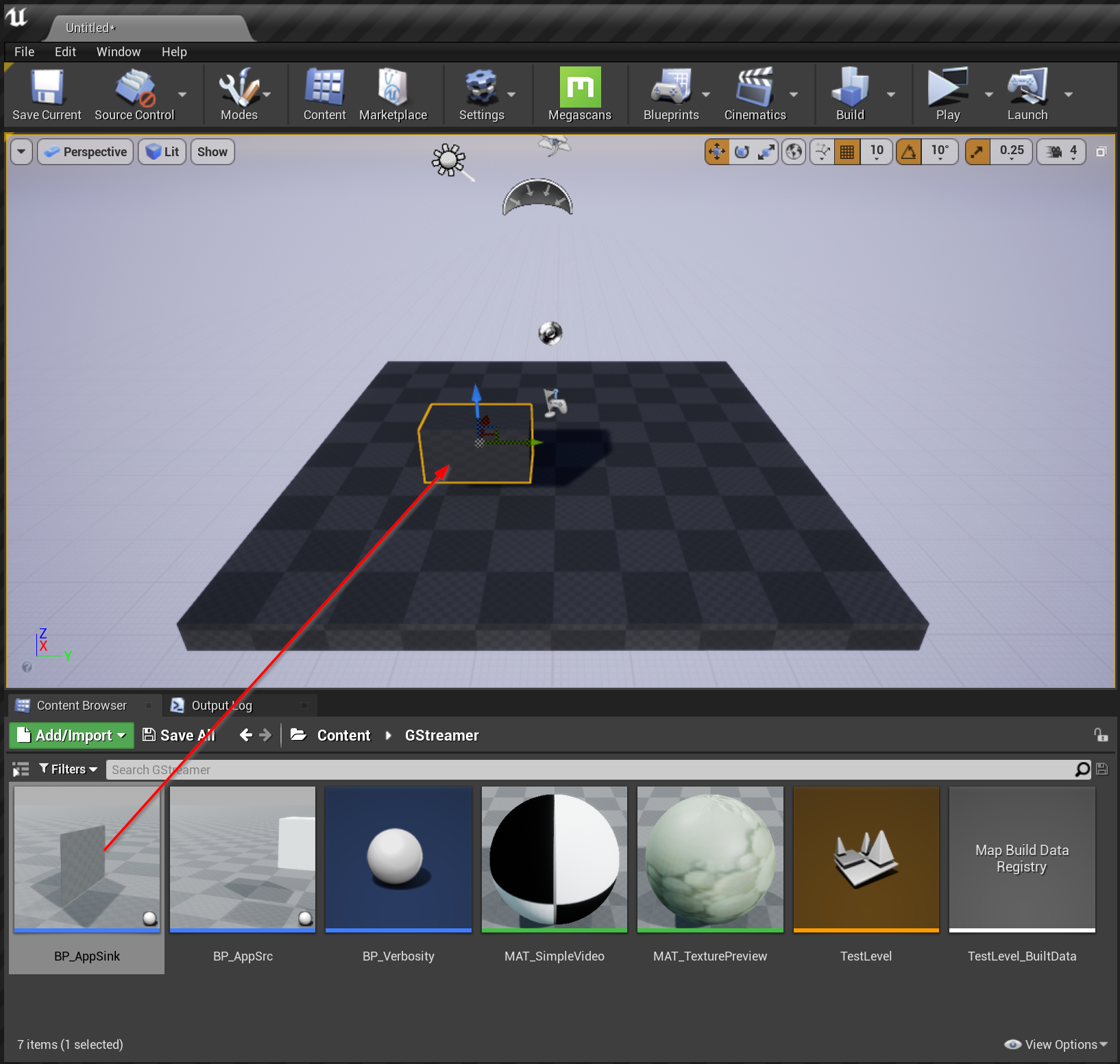
I began with an empty scene and simply dragged a BP_AppSink component into the scene and adjusted it from its default flat plane to a 3D cube:
Then I configured the pipeline using a testvideosrc to produce a video of a bouncing ball:
The full pipeline is quite simple and just configures the video test source, tells which video format to user, and passes the output to the appsink:
It is straightforward to display video content on 3D surfaces within a game in Unreal Engine by utilizing the built-in Media Framework. Supported video sources include static video files as well as a limited number of streaming formats. But what if the streaming video source that you want to display isn’t compatible with Unreal? One option is to use an external program that makes the video available in a format that Unreal can handle. In this post I demonstrate how to do this using the GStreamer multimedia framework.
Besides being a fun exercise in using Unreal Engine together with GStreamer, this may seem a little pointless at first glance. But I have something more advanced in sight in later posts, so please stay tuned.
Failed experiments
Before I dive into the “how to” part of this post, it’s worth mentioning the initial approaches that didn’t work. Although Unreal’s Media Framework documentation seems pretty thorough, it is actually vague on the details of which codecs and stream formats are supported, so I needed to do some experimentation. My hope was that I could get away with simply using gst-launch on the command line to quickly produce a stream that was acceptable to Unreal rather than having to write a program myself (laziness being a virtue), but that was not to be.
My first attempt involved simply producing an HLS stream. This works great in a basic static web page and also plays in VLC, but Unreal, sadly, is not able to render this stream despite the documentation listing HLS as a supported format. This is not meant as a critique of Unreal Engine, but as an illustration of how stated compatibility isn’t always what it seems. The devil is in the details.
Another attempt was to provide a UDP stream from Gstreamer with a hand-crafted SDP file to describe the stream based on this approach. While this works in VLC, browsers were having none of it, so I was not surprised to find that Unreal couldn’t render this stream either.
The remainder of this post describes a “happy path” to a working solution disregarding various other missteps that may or may not have occurred along the way.
Components
For this project I’ll be building two components:
A command-line streamer program that uses GStreamer to provide an RTSP stream of a video source
An Unreal game that renders the video stream onto some objects in a 3D scene
Streamer program
The program will use gst-rtsp-server, which is a GStreamer library for building an RTSP server. One of the great things about GStreamer is that bindings are available for most popular programming languages, so you can pick your language of choice. Often if I am building a prototype I will write it either in Java (because it’s the language I am most experienced in) or Python (because it’s light on syntax), but for this task I decided to use my current most-intrigued-by language: Rust.
I was surprised by how little code is needed to build an RTSP server using gst-rtsp-server. The following is the complete Rust program based heavily on this example code:
usestd::env;usegstreamer_rtsp_server::prelude::*;useanyhow::Error;usederive_more::{Display,Error};#[derive(Debug,Display,Error)]#[display(fmt="Could not get mount points")]structNoMountPoints;#[derive(Debug,Display,Error)]#[display(fmt="Usage: {} LAUNCH_LINE",_0)]structUsageError(#[error(not(source))]String);fnmain()->Result<(),Error>{gstreamer::init()?;letargs:Vec<_>=env::args().collect();ifargs.len()!=2{returnErr(Error::from(UsageError(args[0].clone())));}letmain_loop=glib::MainLoop::new(None,false);letserver=gstreamer_rtsp_server::RTSPServer::new();letmounts=server.mount_points().ok_or(NoMountPoints)?;letfactory=gstreamer_rtsp_server::RTSPMediaFactory::new();factory.set_launch(args[1].as_str());factory.set_shared(true);mounts.add_factory("/test",&factory);let_id=server.attach(None)?;println!("Stream ready at rtsp://127.0.0.1:{}/test",server.bound_port());main_loop.run();Ok(())}
The resulting program is very flexible. The program itself only defines the behaviour of the RTSP server with gst-rtsp-server doing all the heavy lifting and allows you to specify the rest of the Gstreamer pipeline on the command line using gst-launch syntax. This makes it very easy to experiment with different video sources, codecs, transformations, etc. Here is an example command-line that provides an RTSP stream showing a bouncing ball, where the foreground and background colours are swapped every second:
It turned out to be important to use openh264enc above instead of x264enc, because Unreal cannot understand the stream provided by the latter.
To view the stream produced by the program above, the following gst-launch command can be used. It simply connects to the RTSP stream and displays it in a new window. You could also open the stream address (rtsp://127.0.0.1:8554/test) in e.g. VLC. I’ll get to Unreal in the next section.
I began with a new Unreal project based on the blank template:
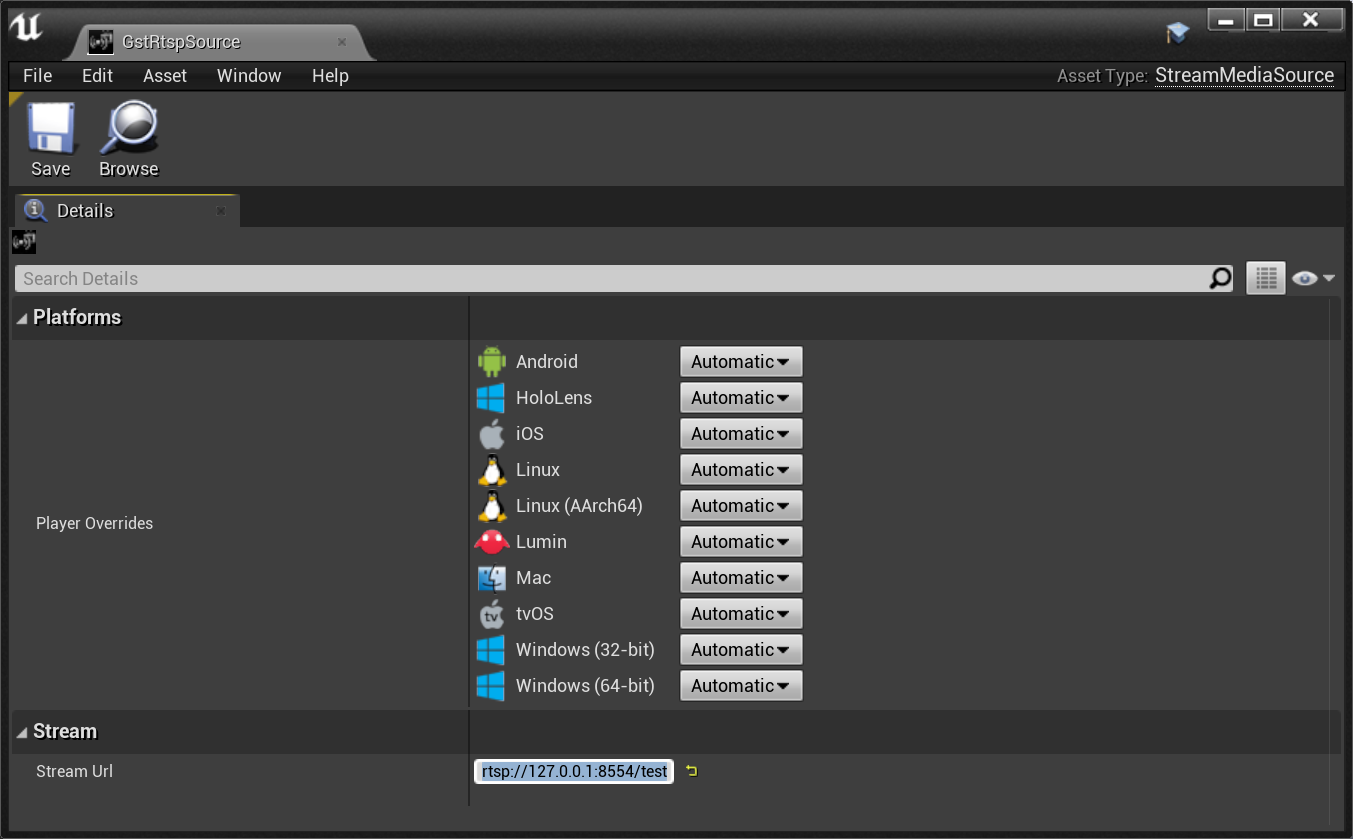
I created a Streaming Media Source(which points to the RTSP URL), a Media Player, associated Media Texture, and Material:
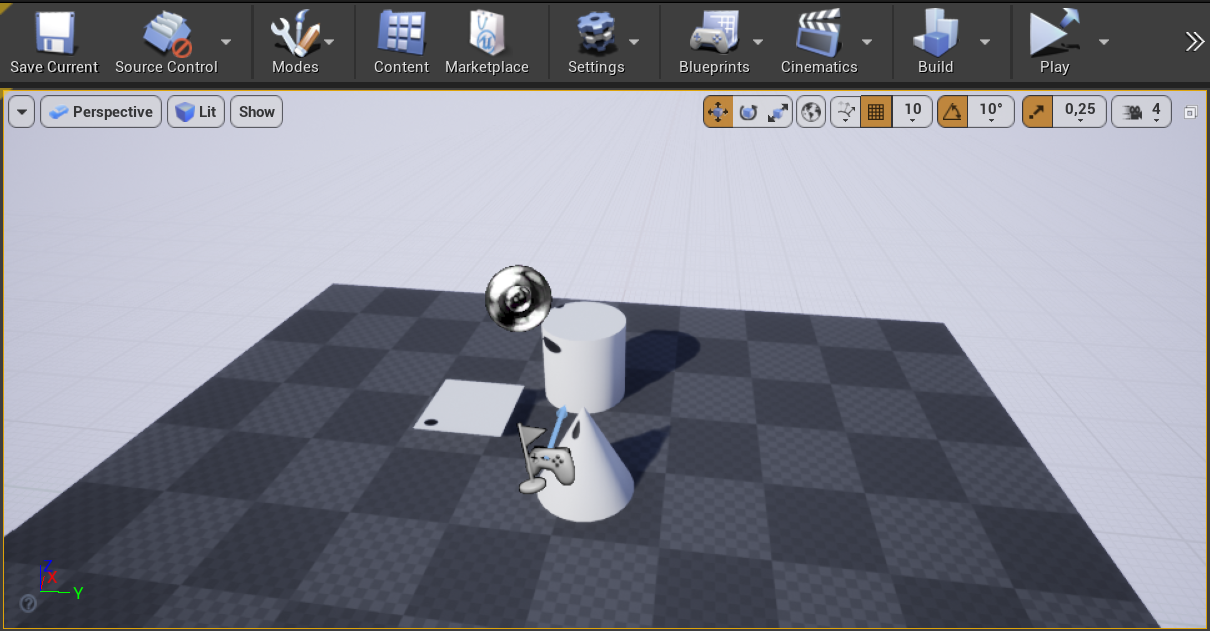
I added a plane and a couple of 3D objects to the scene and applied the video player’s material to them.
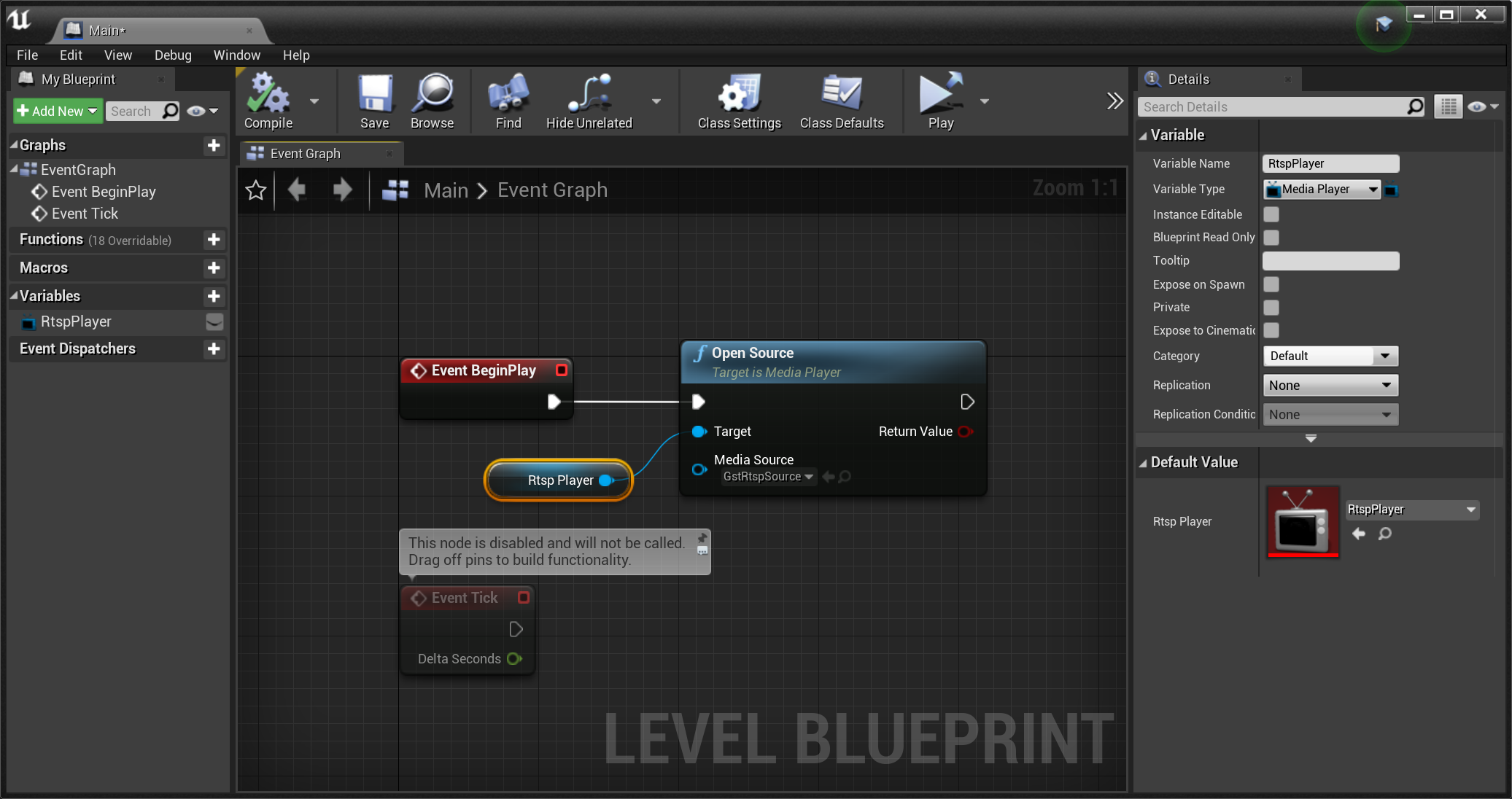
Finally I added a BeginPlay event handler to the level blueprint to start the video when the game starts:
The completed project will receive video from the local streaming source and render it in game. Here is a sample recording of the game with the GStreamer RTSP server streaming the animated ball video:
Live video source
Finally, let’s make this a little more interesting by using a live video source in the GStreamer pipeline. I’ll use my webcam as the input, so that I can see myself in-game. I don’t have to change much in the GStreamer pipeline to make this happen. It’s enough to replace the videotestsrc with ksvideosrc:
“Digital Humans”, I thought, “Wasn’t that also the name of a piece of software that I bought back in the 90’s?” So I went rummaging through a box of old computer stuff: obsolete cables and connectors, CD-ROMS and floppy disks - the usual things I keep for no particular reason. And there it was, a CD-ROM from 1995 titled “Digital Humans”.
If I remember correctly, I had read an article about this in a print magazine and found it intriguing . I ordered a copy via snail mail with a cheque included and received the CD-ROM in the mail some weeks later. How things have changed in a quarter century! Apart from the title, of course this is completely unrelated to what we call Digital Humans today. Nonetheless, this is a very cool technology demonstrator from that time.
About the software
The CD-ROM contains multimedia software published as part of the Visible Human Project. This project “translated a male and a female human body into unlabelled digital atlases, using both color as well as x-ray and magnetic resonance imaging”. The images were generated from the cadavers of two recently deceased individuals who had donated their bodies to science. The x-ray and magnetic resonance images were produced in the usual non-invasive manner, while the color images were produced in a novel - and destructive - way. The frozen cadavers were milled away in 1 mm slices for the male and 0.3 mm slices for the female, and the revealed cross-sections were photographed between each milling step, thus enabling the construction of a fairly high-resolution 3D photogrammetric model of the cadavers to complement the x-ray and MR scans. The software on the CD-ROM allows the user to interactively navigate these 3D images and also includes a lot of interesting video information about the preparations and image processing performed in the Visible Human Project.
Here’s a short video demonstration of the running software (including the rather satisfying Windows 3.1 start-up and shut-down sounds):
I am including some images from the CD sleeve which contain some historically amusing information. You can open the images in a new tab or download them to see them in full resolution.
Note the included 3D glasses! Some of the interactive content is rendered stereoscopically.
Getting it running
Getting this software up and running was a bit of a nostalgia trip.
I started by borrowing my wife’s desktop computer, which luckily still has a DVD/CD-ROM drive installed, in order to copy the contents of the CD onto a flash drive. Because this is 16-bit software that was designed to run on Windows 3.1 or Windows NT, it cannot be run directly in Windows 10. Some sort of virtualization or emulation was required.
I first attempted to install the software into a Linux Docker container with the Wine Windows compatibility layer. I was hopeful when the installer started up correctly and let me choose my installation options. But my hopes were dashed when, shortly after the actual installation began, the installer crashed.
For my second attempt, I followed this tutorial. I downloaded and installed DOSBox which is a DOS emulator that allows you to run old DOS-based programs on modern PCs and operating systems. On top of DOSBox I installed Windows 3.1 from a set of 6 floppy disk images. In order to display more than 16 colours in Windows 3.1, I then installed an updated graphics driver. To get audio output, I installed SoundBlaster drivers. Before long, I had Windows 3.1 running in an application window on my Windows 10 desktop! Installing the Digital Humans software into this environment was straightforward and, as you can see from the video above, it works!
The software crashes occasionally. I’m not sure if this is due to the emulation environment or if the software was always a little unstable. Regardless, revisiting this software was a fun little holiday project.
In a continuation of earlier work on digital humans, I have been building a platform for streaming cloud-rendered avatars to browsers and apps. In this platform, content is rendered in Unreal Engine which in mid-2019 gained a pixel streaming plug-in that utilizes WebRTC to handle streaming of game content to clients over the internet. This has provided me with the opportunity to work intensely with WebRTC, and I’d like to share some thoughts about this technology.
What is WebRTC?
WebRTC is short for Web Real-Time Communications. It provides real-time peer-to-peer streaming of audio, video, and data using a relatively simple API. One of its main intents is to enable video calls between remote users in true peer-to-peer fashion using only their browsers and without requiring them to install a browser plug-in or struggle with firewall settings. WebRTC is a free, open-source standard and is supported by the likes of Apple, Google, and Microsoft (to name a few). It is still working its way through the standardization process of the IETF, but it is already supported in all major browsers and mobile platforms. Furthermore, it is already in wide use in a number of video conferencing solutions, notably Microsoft Teams, Google Meet, GoToMeeting, and others. WebRTC is certainly here to stay.
When establishing a streaming connection between two parties, the ultimate goal is for the parties to stream audio, video, and data directly to one another without going through an intermediary. This serves the dual purposes of
reducing the total network bandwidth and compute resources consumed
reducing the latency of the connection for a better “live” experience
However, establishing a peer-to-peer connection over the internet is a non-trivial matter.
Firewalls
Normally one or both peers are behind firewalls designed to protect them from receiving messages directly from other devices on the internet. The only messages that are allowed in through the firewall are responses to the requests that the peer itself has made. The most well-known example of this is the content received by a browser in response to requests made to a web server. The messages that are allowed through the firewall to the browser all arrive in response to the browser sending a message to the web server saying “please send me this content”. Imagine if any website could freely send data to your browser without being asked. You would probably be staring at thousands of browser tabs filled with nothing but ads!
The reason that websites are able to receive your requests for content is that they have been deliberately configured to receive such requests from the internet at large specifically for this purpose.
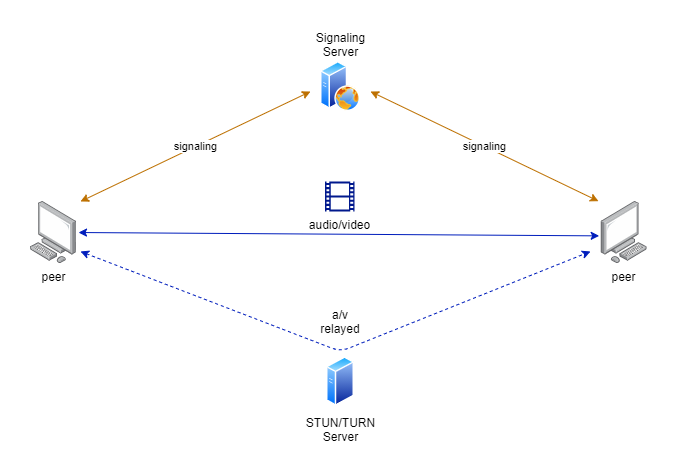
One key feature of WebRTC is that it hides the intricacies of establishing peer-to-peer connectivity from the application developer, so they don’t have to solve this part of the equation themselves. To do this, WebRTC relies on a number of existing standard protocols to do the heavy lifting.
Signaling
WebRTC uses Interactive Connectivity Establishment (ICE) to establish a peer-to-peer connection. Peers use a Session Traversal Utilities for NAT (STUN) server to discover their own public IP address, that is their address as seen from outside their firewall. This address is then shared with the other peer via an ICE message. Using this shared information peers are usually able to establish a direct connection across their firewalls by using “hole-punching” - which is not as sinister as it sounds - to tell their firewalls that they are temporarily willing to receive messages directly from the other peer.
In some cases, however, one or both of the parties’ firewall configurations make it impossible to establish a direct connection, and they must fall back to using a Traversal Using Relays around NAT (TURN) server to relay the streaming data between them. This is less efficient than using a direct connection, because data must pass through the TURN server before reaching its recipient. Also, someone must maintain this server and pay for the bandwidth it uses. Often a single server supports both STUN and TURN functionality.
“Wait a minute”, you may be thinking, “if the peers cannot initially exchange messages directly, then how do they exchange ICE messages?” ICE messages are usually exchanged via an intermediary such as a website or other service to which both parties connect for this exact purpose. In this context the intermediary is referred to as a signaling server, and the exchange of ICE messages as signaling. The WebRTC standard does not prescribe how signaling is accomplished, which is deliberate in order to provide as much flexibility as possible. In principle, signaling messages could even be transmitted by carrier pigeons or smoke signals.
Another important standard used as part of WebRTC signaling is the Session Description Protocol (SDP). SDP messages describe the types of media (e.g. video, audio, and data) that each peer wants to send and receive and which media encodings and formats they are capable of using. Each peer also generates and includes cryptographic keys for one-time use in order to enable end-to-end encryption of streaming data.
Once SDP and ICE have done their job the peers now have a path to start streaming data to one another. At this point yet another standard, the Real Time Streaming Protocol (RTSP), is used to actually send and receive multimedia data over the established connection. I won’t get into the many details of RTSP as that could easily fill a separate post, but suffice it to say that this takes care of things like optimizing data streams for the available bandwidth, retransmission of lost data, and many other essentials of successful streaming.
Simple API
At this point you probably have the impression that WebRTC is quite a complex beast supported by many additional standards and protocols and that using WebRTC in your own development projects might be rather daunting. Certainly building something comparable from scratch would be a monumental undertaking. But how difficult is it for a developer to work with WebRTC?
The JavaScript API that WebRTC exposes to web developers in the browser is deceptively simple. It has just three main entry points:
navigator.mediaDevices.getUserMedia() – gathers information about available devices (microphones, camera, and the screen) and their capabilities while prompting the user for permission to access these devices
RTCPeerConnection – manages the connection to the remote peer, including the actual audio and video streams
RTCDataChannel – manages data channels to exchange custom messages (not audio and video) with the peer via the RTCPeerConnection
The bulk of the interaction with a custom web application will be with RTCPeerConnection. It has a multitude of methods and callbacks that must be orchestrated with both the frontend code and the signaling server. However, it does all the heavy lifting associated with ICE, SDP, and RTSP, allowing the developer to concentrate on their application-specific functionality while getting streaming audio and video almost for free. The RTCPeerConnection API produces and consumes all the signaling messages for you – all you have to do is manage the transmission of these messages between peers.
I won’t clutter this post by including code, since code samples are plentiful. Examples can be found of functioning websites offering simple WebRTC calls between connected clients. Some are as short as a few hundred lines of JavaScript. WebRTC APIs are also available for app developers on Android and iOS, and these APIs closely resemble the browser API. This makes it about as easy to incorporate WebRTC in a mobile app as in a web page.
This out of the box simplicity is great when you are developing apps or websites for streaming between users on different frontend devices. But what if you are working with a client/server scenario?
WebRTC and digital humans
Initially, the digital human scenario may look more like a client/server scenario than a peer-to-peer scenario. After all, rather than connecting to another user who is physically located somewhere else in the world, a user connects to a website or service on the internet in order to interact with an avatar. However, this is easily viewed as a special case of peer-to-peer by considering the avatar not as a service but as a peer on an equal footing with the human user.
While the sample web server and scripts provided by Unreal with their pixel streaming plug-in are straightforward to get up and running, and they do a good job for demonstration purposes, they are not directly suited to the digital human scenario. The sample scripts seem to be designed mainly to allow multiple spectators to view a game being played by a single player, while the digital human scenario calls more for a one-to-one interaction between a human and an avatar. Additionally, the scripts do not address issues of scaling to 10s, 100s, or even 1000s of such simultaneous interactions.
More importantly, the digital human must be able to see and hear the user, and the pixel streaming plug-in does not support the streaming of audio and video from the user to Unreal. The solution that I am involved in building side-steps this limitation by using a separate server-side component to receive the audio and video from the user and perform Voice Activity Detection (VAD) and subsequently speech recognition and emotion detection. Basically, two separate WebRTC connections are established, one between Unreal and the user and the second between the user and the VAD component. On the server side, the VAD component is able to communicate directly with Unreal, because they don’t have to contend with the limitations otherwise imposed by firewalls.
Implementing the server side VAD component introduced an additional challenge. The WebRTC APIs described above are designed to run within their respective client frameworks either as part of a mobile app or within a browser. They are therefore not applicable in a server setting. Luckily there are libraries available written in a variety of server side programming languages such as node-webrtc for NodeJS and aiortc for Python.
The most feature complete and high-performance library I have found is GStreamer. GStreamer is a multiplatform multimedia framework written in C, and includes a feature-rich WebRTC plug-in even though its functionality goes far beyond WebRTC. It also has solid language bindings for most popular programming languages, which means that it can be used in a variety of settings including servers and embedded devices.
Summary
Even though WebRTC is not yet a finalized standard, I think it is a no-brainer if you want to integrate peer-to-peer audio/video streaming in your own web application or mobile app. As I have shown, it is also useful in other contexts where its peer-to-peer nature is perhaps not so readily apparent. WebRTC is a great example of how a ton of functionality and complexity can be hidden behind a small, deceptively simple API. As is often the case, the devil is in the details, and moving beyond basic examples quickly forces you to consider those details.